adsp-21160m
–2– rev. 0
特性 (持续)
单独的 操作指南 多样的 数据 (simd)
Architecture 提供:
二 computational 处理 elements
concurrent 执行
—
各自 处理 元素
executes 这 一样 操作指南, 但是 运作 在
不同的 数据
代号 兼容性
—
在 组装 水平的, 使用 这
一样 操作指南 设置 作 这 adsp-2106x
SHARC DSPs
parallelism 在 buses 和 computational 单位 准许:
单独的-循环 执行 (和 或者 没有 simd) 的: 一个
乘以 运作, 一个 alu 运作, 一个 双
记忆 读 或者 写, 和 一个 操作指南 fetch
transfers 在 记忆 和 核心 在 向上 至 四
32-位 floating- 或者 fixed-要点 words 每 循环
accelerated fft butterfly computation 通过 一个
乘以 和 增加 和 减去
4m 位 在-碎片 双-ported sram 为 独立
进入 用 核心 处理器, host, 和 dma
dma 控制 支持:
14 零-overhead dma 途径 为 transfers 在
adsp-21160m 内部的 记忆 和 外部
记忆, 外部 peripherals, host 处理器, 串行
端口, 或者 link 端口
64-位 background dma transfers 在 核心 时钟 速,
在 并行的 和 全部-速 处理器 执行
560m 字节/s 转移 比率 在 iop 总线
host 处理器 接口 至 16- 和 32-位
微处理器
4g 文字 地址 范围 为 止-碎片 记忆
记忆 接口 支持 可编程序的 wait 状态
一代 和 页-模式 为 止-碎片 记忆
multiprocessing 支持 提供:
glueless 连接 为 可称量的 dsp multiprocessing
Architecture
distributed 在-碎片 总线 arbitration 为 并行的 总线
连接 的 向上 至 六 adsp-21160ms 加 host
六 link 端口 为 要点-至-要点 connectivity 和 排列
Multiprocessing
串行 端口 提供:
二 40m 位/s 同步的 串行 端口 和
companding 硬件
独立 transmit 和 receive 功能
tdm 支持 为 t1 和 e1 接口
64-位 宽 同步的 外部 端口 提供:
glueless 连接 至 异步的 和 sbsram
外部 memories
向上 至 40 mhz 运作
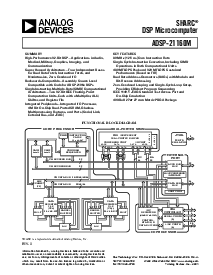
一般 描述
这 adsp-21160m sharc dsp 是 这 第一 处理器 在
一个 新 家族 featuring 相似物 设备’ 超级的 harvard
architecture. easing portability, 这 adsp-21160m 是
应用 源 代号 兼容 和 第一 一代
adsp-2106x sharc dsps 在 sisd (单独的 操作指南,
单独的 数据) 模式. 至 引领 有利因素 的 这 处理器’s
simd (单独的 操作指南, 多样的 数据) 能力, 一些
代号 改变 是 需要. 像 其它 sharcs, 这
adsp-21160m 是 一个 32-位 处理器 那 是 优化 为
高 效能 dsp 产品. 这 adsp-21160m
包含 一个 80 mhz 核心, 一个 双-ported 在-碎片 sram, 一个
整体的 i/o 处理器 和 multiprocessing 支持, 和
多样的 内部的 buses 至 eliminate i/o bottlenecks.
这 adsp-21160m introduces 单独的-操作指南,
多样的-数据 (simd) 处理. 使用 二 computa-
tional 单位 (adsp-2106x sharc dsps 有 一个), 这
adsp-21160m 能 翻倍 效能 相比 这
adsp-2106x 在 一个 范围 的 dsp algorithms.
fabricated 在 一个 状态 的 这 art, 高 速, 低 电源
cmos 处理, 这 adsp-21160m 有 一个 12.5 ns instruc-
tion 循环 时间. 和 它的 simd computational 硬件
运动 在 80 mhz, 这 adsp-21160m 能 执行 480
million math 行动 每 第二.
表格 1显示 效能 benchmarks 为 这
adsp-21160m.
这些 benchmarks 提供 单独的-频道 extrapolations 的
量过的 双-频道 处理 效能. 为 更多
信息 在 benchmarking 和 optimizing dsp 代号 为
单独的- 和 双-频道 处理, 看 相似物 设备’s
网站.
这 adsp-21160m 持续 sharc’s 工业-leading
standards 的 integration 为 dsps, 结合 一个
高-效能 32-位 dsp 核心 和 整体的, 在-碎片
系统 特性. 这些 特性 包含 一个 4m 位 双
ported sram 记忆, host 处理器 接口, i/o
处理器 那 支持 14 dma 途径, 二 串行 端口,
六 link 端口, 外部 并行的 总线, 和 glueless
multiprocessing.
表格 1. adsp-21160m benchmarks
benchmark algorithm 速
1024 要点 complex fft (radix 4, 和
倒置)
115 µs
fir 过滤 (每 tap) 6.25 ns
iir 过滤 (每 biquad) 25 ns
矩阵变换 乘以 (pipelined)
[3
3]
[3
1]
56.25 ns
矩阵变换 乘以 (pipelined)
[4
4]
[4
1]
100 ns
分隔 (y/x) 37.5 ns
inverse 正方形的 root 56.25 ns
dma 转移 比率 560m 字节/s