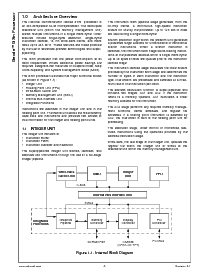
修订 3.1 9 www.国家的.com
Architecture Overview (
持续
)
Geode™ GXm 处理器
1.2 FLOATING 要点 单位
这 FPU (floating 要点 单位) 接口 至 这 integer 单位
和 这 cache 单位 通过 一个 64-位 总线. 这 FPU 是 x87-
操作指南-设置 兼容 和 adheres 至 这 ieee-754
标准. 因为 almost 所有 产品 那 包含
FPU 说明 也 包含 integer 说明, 这
GXm processor’s FPU achieves 高 效能 用
完成 integer 和 FPU 行动 在 并行的.
FPU 说明 是 dispatched 至 这 pipeline 在里面 这
integer 单位. 这 地址 计算 平台 的 这 pipeline
checks 为 记忆 管理 exceptions 和
accesses 记忆 operands 为 使用 用 这 fpu. Once 这
说明 和 operands 有 被 提供 至 这 fpu,
这 FPU 完成 操作指南 执行 independently 的
这 integer 单位.
1.3 写-后面的 CACHE 单位
这 16 KB 写-后面的 unified cache 是 一个 数据/操作指南
cache 和 是 配置 作 四-方法 设置 associative. 这
cache stores 向上 至 16 KB 的 代号 和 数据 在 1024 cache
线条.
这 GXm 处理器 提供 这 能力 至 allocate 一个 por-
tion 的 这 L1 cache 作 一个 scratchpad, 这个 是 使用 至
accelerate 这 模拟的 系统 Architecture algorithms 作
好 作 为 一些 graphics 行动.
1.4 记忆 管理 单位
这 记忆 管理 单位 (mmu) translates 这 lin-
ear 地址 有提供的 用 这 integer 单位 在 一个 物理的
地址 至 是 使用 用 这 cache 单位 和 这 内部的 总线
接口 单位. 记忆 管理 程序 是 x86-
兼容, adhering 至 标准 paging mechanisms.
这 MMU 也 包含 一个 加载/store 单位 那 是 responsi-
ble 为 scheduling cache 和 外部 记忆 accesses.
这 加载/store 单位 包含 二 效能-
enhancing 特性:
•
加载-store reordering
那 给 priority 至 记忆
读 必需的 用 这 integer 单位 在 写 至
外部 记忆.
•
记忆-读 bypassing
那 排除 unnecessary
记忆 读 用 使用 有效的 数据 从 这 执行
单位.
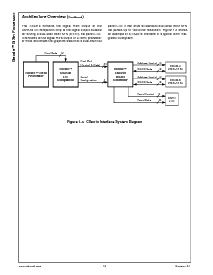
1.4.1 内部的 总线 接口 单位
这 内部的 总线 接口 单位 提供 一个 桥 从 这
GXm 处理器 至 这 整体的 系统 功能 (i.e.,
记忆 subsystem, 显示 控制, graphics pipeline)
和 这 PCI 总线 接口.
当 外部 记忆 进入 是 必需的, 这 物理的
地址 是 计算 用 这 记忆 管理 单位
和 然后 passed 至 这 内部的 总线 接口 单位, 这个
translates 这 循环 至 一个 x-总线 循环 (这 x-总线 是 一个
国家的 半导体 专卖的 内部的 总线 这个
提供 一个 一般 接口 为 所有 的 这 系统 mod-
ules). 这 x-总线 记忆 循环 now 是 arbitrated 在
其它 pending x-总线 记忆 requests 至 这 SDRAM
控制 在之前 完成.
在 增加, 这 内部的 总线 接口 单位 提供 config-
uration 控制 为 向上 至 20 不同的 regions 在里面 系统
记忆 和 独立的 控制 为 读 进入, 写
进入, cacheability, 和 PCI 进入.
1.5 整体的 功能
这 GXm 处理器 integrates 这 下列的 功能 tra-
ditionally 执行 使用 外部 设备:
• 高-效能 2D graphics accelerator
• 独立的 CRT 和 TFT 数据 paths 从 这 显示
控制
• SDRAM 记忆 控制
• PCI 桥
这 处理器 有 也 被 增强 至 支持
国家的 Semiconductor’s 专卖的 模拟的 系统
Architecture (vsa) implementation.
这 GXm 处理器 实现 一个 Unified 记忆 archi-
tecture (uma). 用 使用 国家的 Semiconductor’s dis-
播放 压缩 技术 (dct), 这 效能
降级 固有的 在 传统的 UMA 系统 是 elimi-
nated.
1.5.1 Graphics Accelerator
这 graphics accelerator 是 一个 全部-featured GUI (graphical
用户 接口) accelerator. 这 graphics pipeline imple-
ments 一个 bitBLT engine 为 框架 缓存区 bitBLTs 和 rect-
angular fills. 额外的 说明 在 这 integer 单位 将
是 processed, 作 这 bitBLT engine assists 这 CPU 在 这
bitBLT 行动 那 引领 放置 在 系统 mem-
ory 和 这 框架 缓存区. 这个 结合体 的 硬件
和 软件 是 使用 用 这 显示 驱动器 至 提供 非常
快 transfers 在 两个都 方向 在 系统 记忆
和 这 框架 缓存区. 这 bitBLT engine 也 牵引 ran-
domly-朝向 vectors, 和 scanlines 为 polygon fill. 所有
的 这 pipeline 行动 描述 在 这 下列的 列表
能 是 应用 至 任何 bitBLT 运作.
•
模式 记忆.
Render 和 8x8 dither, 8x8 mono-
chrome, 或者 8x1 颜色 模式.
•
颜色 expansion.
Expand monochrome bitmaps 至
全部-depth 8- 或者 16-位 colors.
•
transparency.
抑制 绘画 的 background
pixels 为 transparent text.
•
Raster 行动.
Boolean 运作 结合
源, destination, 和 模式 bitmaps.